In this post we are going to play around with full text searching Linux man pages using Elasticsearch.
The idea
We will:
- setup an Elasticsearch instance locally
- create an index for the data
- feed the index with the man pages of the OS
- create a search method for full text searching
- full text search the man pages
The code
I have gathered the code snippets you will find here in a script called elman and it is available on GitHub so after reading this post to get the idea, you can experiment by modifying it as you please.
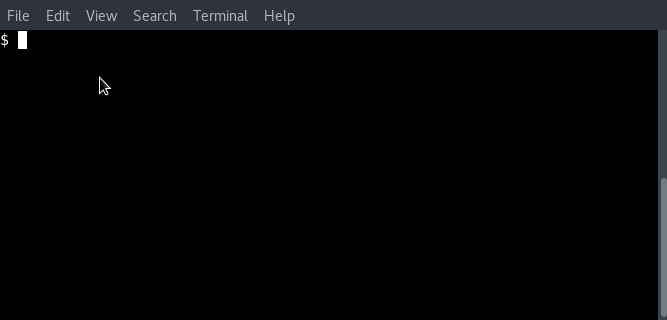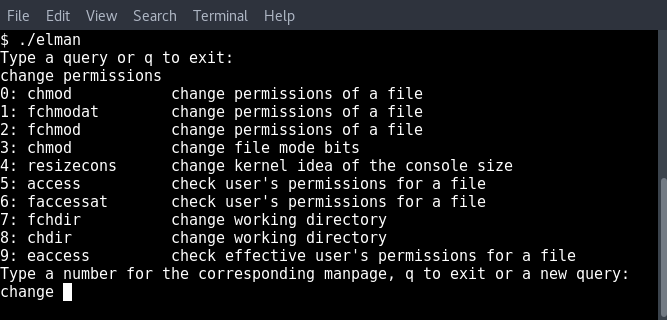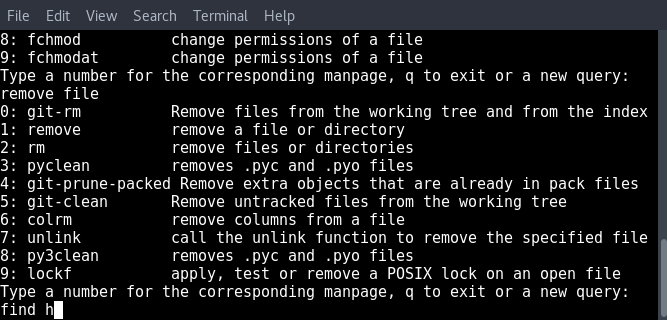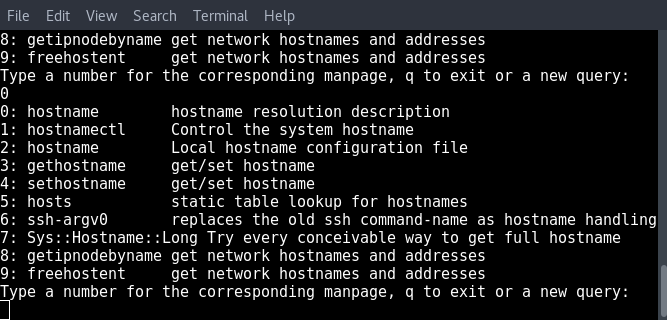
Let’s start.
Prerequisites
Ruby
You should have ruby installed on your system. I use RVM to manage multiple ruby versions installed on my system. If you want to go with that too, you can find instructions for installing the tool in its homepage and for installing ruby versions (a.k.a. rubies) the related documentation page.
This tutorial is using Ruby 2.4.2. You can check yours using: ruby --version or via RVM with rvm list.
Elasticsearch
Providing instructions for installing Elasticsearch is out of this post’s scope. I recommend visiting the tool’s related documenation site.
After the installation, just make sure to start the service if it’s not started.
You can check that with curl http://localhost:9200.
It should give something like:
{
"name" : "asdfasdf",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "asasdfdf-as",
"version" : {
"number" : "6.0.0",
"build_hash" : "asdf",
"build_date" : "2017-11-10T18:41:22.859Z",
"build_snapshot" : false,
"lucene_version" : "7.0.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
As you can see, we will use elasticsearch version 6.0.0 in this tutorial.
Hands on
We will be working in the awesome Ruby interactive shell (irb) but before starting it there’s a gem we need to install.
The elasticsearch gem
The elasticsearch gem is the official library provided by Elastic to interact with Elasticsearch instances in Ruby.
Install the gem and its dependencies use the following command in your terminal:
gem install elasticsearch
Ruby interactive shell
Start the Ruby interactive shell with:
irb
Load the Elasticsearch library we previously installed with:
require 'elasticsearch'
You should see something like the following:
>> require 'elasticsearch'
=> true
>>
From now on, in our session we can use the gem’s provided classes and modules to interact with Elasticsearch.
Creating the client
We have to create an Elasticsearch::Client instance through which we will execute commands on the index.
In irb type:
@client = Elasticsearch::Client.new host: 'localhost', port: '9200'
Check the cluster’s health to make sure everything is right:
client.cluster.health
=> {"cluster_name"=>"elasticsearch", "status"=>"yellow", "timed_out"=>false, "number_of_nodes"=>1, "number_of_data_nodes"=>1, "active_primary_shards"=>10, "active_shards"=>10, "relocating_shards"=>0, "initializing_shards"=>0, "unassigned_shards"=>10, "delayed_unassigned_shards"=>0, "number_of_pending_tasks"=>0, "number_of_in_flight_fetch"=>0, "task_max_waiting_in_queue_millis"=>0, "active_shards_percent_as_number"=>50.0}
Make sure that the status from the output hash is not red.
Creating the index
Let’s name the index elastic_manpages and set that it is going to have three properties:
-
command: the Linux command (even though there are man pages for other stuff like
time.confwhich is a configuration file) -
description: the short description provided in the top of the man page, in the
NAMEsection -
manpage: the corresponding man page
Create the index with the following command:
@client.indices.create index: 'elastic_manpages',
body: {
mappings: {
document: {
properties: {
command: {
type: :text
},
description: {
type: :text,
analyzer: :english
},
manpage: {
type: :text,
analyzer: :english
}
}
}
}
}
As you can see, we assigned the english analyzer to the description and manpage properties.
Why? Quoting the documentation on Language analyzers:
They are able to take the peculiarities of the specified language into account. For instance, the english analyzer comes with a set of English stopwords (common words like and or the that don’t have much impact on relevance), which it removes. This analyzer also is able to stem English words because it understands the rules of English grammar.
After typing the command, you should get a response like this one:
=> {"acknowledged"=>true, "shards_acknowledged"=>true, "index"=>"elastic_manpages"}
Indexing the man pages
Time to index the man pages. We are going to use the apropos command to list all entries of the mandb.
all_pages = `apropos .`.split "\n"
The all_pages variable now contains a list of all man entries in the following format:
erb (1) - Ruby Templating
Note: the (1) part above defines what section of the manual the page is from.
For each entry of this list, we need to:
- export the command and the description
- retrieve the man page for each command
- index a new document mapping the values of the previous items to the appropriate properties.
To split the raw apropos entry to the desired field, we will use the following regex:
/(.*)\s\(\d*.*\)\s*-\s*(.*)/
You can check that is working on Rubular.
Back in irb:
apropos_regex = /(.*)\s\(\d*.*\)\s*-\s*(.*)/
all_pages.each do |line|
matches = apropos_regex.match line
command = matches[1]
description = matches[2]
manpage = `man #{command}`
@client.index index: 'elastic_manpages',
type: :document,
body: {
command: command,
description: description,
manpage: manpage
}
end
It will take some time depending on your hardware and the amount of man pages on your OS. Wait for it to end. During the process of indexing you might see some warnings for some pages but don’t worry, the process will complete after all and we don’t care that much about them not being indexed correctly for the purpose of this tutorial.
Creating the search method
Now will create a method for full text searching so that we can execute it more than once to search.
In irb:
def search(term)
result = @client.search index: 'elastic_manpages',
size: 10,
body: {
query: {
multi_match: {
query: term,
type: :cross_fields,
fields: ['command', 'description^3', 'manpage^3'],
operator: :or,
tie_breaker: 1.0,
cutoff_frequency: 0.1
}
}
}
result['hits']['hits'].map{ |hit| { command: hit['_source']['command'],
description: hit['_source']['description'],
manpage: hit['_source']['manpage'] } }
end
Notes on the search definition
size: 10: set the size of the results to be 10multi_match: because we want to search on multiple fields (command,description,manpage)type: :cross_fields: The cross_fields type is particularly useful with structured documents where multiple fields should match (read more here)tie_breaker: add the scores for each term of the query (read more here)cutoff_frequency: it prevents scoring / iterating high frequency terms and only takes the terms into account if a more significant / lower frequency term matches a document (read more here)
Play time!
That’s it. Time to check what we have created.
In irb:
search('edit image').each{ |a| puts "#{a[:command].ljust(20)} - #{a[:description]}"}; nil
gimp-2.8 - an image manipulation and paint program.
gimp - an image manipulation and paint program.
Image::Magick::Q16 - objected-oriented Perl interface to ImageMagick (Q16). Use it to create, edit, compose, or convert ...
gimp-console-2.8 - an image manipulation and paint program.
gimp-console - an image manipulation and paint program.
bitmap - bitmap editor and converter utilities for the X Window System
bmtoa - bitmap editor and converter utilities for the X Window System
atobm - bitmap editor and converter utilities for the X Window System
mailcap.order - the mailcap ordering specifications
xwd - dump an image of an X window
=> nil
search('change owner').each{ |a| puts "#{a[:command].ljust(20)} - #{a[:description]}"}; nil
chown - change file owner and group
chown - change ownership of a file
fchownat - change ownership of a file
fchown - change ownership of a file
lchown32 - change ownership of a file
chown32 - change ownership of a file
fchown32 - change ownership of a file
lchown - change ownership of a file
fchmod - change permissions of a file
XSetEventQueueOwner - set event queue owner on a shared Xlib/XCB connection
=> nil
You can modify the search definition as you please. Check more on the multi_match query here.
As always, cat photo.

 (
(